Many people think monitoring and QA are the same thing. They suggested that ultimately, we should be able to run the same QA test automation in production, as a monitoring approach to verify whether everything is working. Some said,
“your monitoring is doing comprehensive semantics checking of your entire range of services and data, at which point it’s indistinguishable from automated QA.”
I kind of disagree with that. For two reasons:
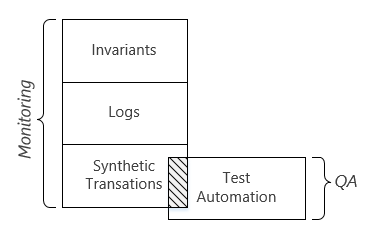
Reason 1. There are three monitoring approaches: 1) invariants, 2) metrics & logs, 3) synthetic transactions. By suggesting that monitoring and QA test automation are the same thing, people are equaling monitoring to synthetic transaction. However, the synthetic transaction approach is not sufficient to the need of live site monitoring. Synthetic transactions has some limitations:
- Representativeness. The fact that the test automation can provision a virtual machine in production doesn’t guarantee all the users can do so too.
- Cost. Every time the test automation provisions a new virtual machine, there is a cost on the system across the layers. As we increase the coverage of the monitoring and reduce the MTTD (mean time to detect), such overhead will become significantly a lot. In other words, using QA test automation for monitoring is not very economic. Plus, the cost will exponentially increase and the marginal return of investment will drop as we use synthetic transactions to cover more granular scenarios. In the past, I have seen for multiple times that groups went down such a slippery slope:
- In the beginning, the team’s live site monitoring only provision one Small size Windows Server 2008 virtual machine in West US every 10 minutes.
- Later, there happened a live site bug which only affected virtual machines running Windows Server 2012 OS. So instead of only covering Windows Server 2008, the team changed to cover all the OS types, including a few mainstream distro of Linux. That increased the number of synthetic virtual machines from one per 10 minutes to a half dozen per 10 minutes.
- There happened another live site bug which caused virtual machine provisioning failing in some regions but not the others. Unfortunately, the synthetic transactions didn’t catch it because it only creates virtual machines in West US. Then the team changed to cover all regions rather than just West US. That increase the number of synthetic virtual machines by another 10x.
- The team was challenged to reduce the MTTD. They figured that 10 minutes interval was too long and they reduced it to every 5 minutes. That doubled the amount of synthetic virtual machines.
- The team also ran into a live site issue that only affects A8 and A9 sizes. So on and so on. In a year or two, the number of synthetic virtual machines increased from 1 to 100s.
- Blind spots. By running synthetic transactions, you will verify the scenarios that you know about and catch issues in these scenarios. But there are other scenarios (often corner cases) that you don’t know about or you don’t think it would be different. Hence, synthetic transactions won’t cover those scenarios and those are the places where some nasty live site incidents happened.
I believe that in live site monitoring, the other two approaches (logs and invariants) are needed to compensate these limitations of synthetic transactions. The three approaches are all useful and we need to effectively choose one or a combination of two or three for different purposes.
Reason 2. There are some important differences between the synthetic transactions used in monitoring vs. the test cases in QA test automation. By suggesting that monitoring and QA test automation are the same thing, people are equaling synthetic transactions to QA test automation. That’s not the case. Leaving aside the fact that not all the test cases can run in production, not all the test cases need to run in production. Just for a couple examples:
- In QA test automation, a test case will verify that provisioning a new virtual machine must fail when the size is not among the supported sizes list (e.g. the output of ListSizes API call). Once our code have passed this test case in the in-house test pass, we believe it will behave the same way in production.
- In QA test automation, a test case will verify that a customer can create a new virtual in the new A10 size if and only if the customer has enrolled in the “LargeVirtualMachine” beta feature. Once our code have passed this test case in the in-house test pass, we believe when the code is running in production, it will also correctly honor the enrollment status of the beta feature.
In both examples, we don’t need to run these test cases in production as a part of the live site monitoring.
The below chart illustrates the two reasons above (the scale is not in proportion):

[…] Part 1, I mentioned that there are three monitoring approaches: a) invariants, b) logs, c) synthetic […]
[…] this blog series (Part 1, Part 2, Part 3) captures the mind model that I use to look at live site monitoring. This model […]
agree QA doesn’t equals to live site monitoring. But I don’t understand why you are think “synthetic traffic” is part of monitoring. In our system, log and counter is most key point for live site monitoring and it’s works quite well regardless of country/region, device type, clients… we don’t bother to create those synthetic traffic to cover the monitoring, live traffic is enough. But of course, we indeed have testing in production, but I don’t think it’s part of monitoring, but more like it’s a way to help us to understand the production well, like some perf testing on production to understand the max TPS we can support, the bottleneck of our system..